Build An Agentic Amazon Backtest Operating Model With Bedrock AgentCore And Strands Agents
Institutional AMZN portfolio research requires timing governance, drawdown attribution, benchmark context, factor discipline, execution ledgers, and cloud auditability. Build a long-only backtest factory using Amazon Bedrock AgentCore, Strands Agents, AWS data controls, custom Cerebro-style simulation, Sharpe analytics, trade history, and FSI risk language for responsible position management review and oversight.
Content presented here focuses exclusively on legitimate financial planning education, aiming to improve understanding of concepts, methodologies, and analytical approaches without promoting any specific securities, strategies, or market participation decisions.
No Personalized Advice:
No personalized recommendations, solicitations, or assurances are provided, and no guarantees of future performance, outcomes, or returns are implied, expressed, or otherwise suggested under any circumstances within this educational material.
Data Limitations:
Uploaded results rely on deterministic, offline data because live data was unavailable within the sandbox environment, and therefore outputs should be interpreted as illustrative examples rather than real time analyses.
Long-Only Scope:
All research language used is long only, avoiding options, puts, short selling, or bearish strategies, ensuring the discussion remains focused on traditional asset ownership and positive directional exposure concepts overall.
Build The Operating Model Before Debating The Result
A five-hundred-percent unrealized gain can make a research deck feel persuasive, but an institution first needs to know who requested the run, which tool executed it, where the data came from, which rules were approved, and what evidence was preserved. This first custom-engine article establishes that operating model before discussing strategy rankings.
The articles do not recommend buying, selling, or holding Amazon. They show how governed research workflow can turn a position-management question into controlled evidence.
Positioning
The trader voice in this part is an operating-model sponsor: experienced enough to respect the market, but focused mainly on process design. The article asks how AgentCore, Strands Agents, a custom Cerebro-style engine, and AWS artifact controls can help teams review AMZN timing without handing judgment to automation.
The Client Problem Worth Solving
The client problem in part 1 is fragmented operating ownership. Portfolio managers, risk reviewers, engineers, and compliance stakeholders often inspect different versions of the same research story. The operating model gives them one path from request to policy check, simulation, ledger, chart, summary, and committee review.
Business Outcomes This Workflow Supports
This workflow supports cleaner ownership boundaries, reusable agent roles, consistent artifact generation, and a stronger path from technical results to governance discussion. Its value is not that the first-ranked strategy becomes an answer; its value is that every ranked strategy can be inspected through the same evidence package.
Table Of Contents
Part 1: Institutional Opening And Trading Voice — Establishes the institutional trading voice, AMZN position context, communication discipline, and education-only framing.
Part 2: Business Problem And Position Discipline — Defines why profitable long positions still need evidence-based entry, exit, sizing, drawdown, benchmark, and audit controls.
Part 3: AgentCore And Strands Architecture — Explains agent roles, bounded authority, controlled tools, logged outputs, and reviewable financial-services workflow design.
Part 4: Operating Model Code Path And Engine Controls — Maps inputs, indicators, signals, execution logic, costs, ledgers, metrics, and review controls into trader language.
Part 5: Top Strategy Records And Operating Lessons — Reviews leading strategy records through return, volatility, Sharpe, drawdown, trade count, win rate, and feasibility.
Part 6: Executive Close And Governance Review — Turns code, charts, and ledgers into committee language and explains why human judgment remains the final control.
Part 7: Operating Model Boundary And Governance Lenses — Groups the integrated main-article details and governance lenses so readers can review policy, artifacts, demo-data limits, and accountability together.
Part 8: AgentCore, Strands, And Code Talk Implementation — Separates the operating model, Strands entrypoint, and custom engine code into one focused implementation section.
Part 9: Top Strategy Records And Trader Review — Collects the top strategy records into a single performance-review section with code talk and lessons for each rule.
Part 10: Trading Lessons, Evidence Notes, And Governance Close — Finishes with trading lessons, source notes, committee narrative, and final governance checklist.
Part 1: Institutional Opening And Trading Voice
Related summary: Establishes the institutional trading voice, AMZN position context, and communication discipline. It frames the article as education and planning support, not investment advice, recommendation, solicitation, or a promise of future returns.
The opening should not celebrate a position before it explains the control problem. A strong AMZN gain can create confidence, but confidence is not a substitute for entry discipline, exit discipline, sizing logic, drawdown tolerance, and benchmark-relative review.
The useful practice-note message is absorbed here as speaking discipline: use evidence language, state the data mode, name the assumptions, and avoid promising certainty. The article should read like institutional research, not like a promotional pitch.
Part 2: Business Problem And Position Discipline
Related summary: Defines why profitable long positions still require evidence-based entry, exit, sizing, drawdown, and benchmark controls. It connects portfolio management, risk oversight, technology governance, and audit requirements into one reviewable workflow.
The business problem is fragmented evidence. Portfolio teams want speed, risk teams want traceability, technology teams want secure orchestration, and compliance teams want appropriate language. The workflow aligns those needs by creating a repeatable research path.
Position discipline means every strategy should answer the same questions: why enter, why exit, how much exposure, what cost assumption, what drawdown path, and what benchmark context. Those questions are now part of the main article body rather than a note at the end.
Part 3: AgentCore And Strands Architecture
Related summary: Explains the agentic architecture by separating orchestrator, data agent, strategy agent, backtest tool, risk reviewer, and governance checker. Each component has bounded authority, controlled tools, and logged outputs for financial-services review.
The architecture starts with role clarity. The Quant Orchestrator owns request decomposition, the Market Data Agent owns data status, the Strategy Agent owns signal definitions, the Backtest Engine Tool owns simulation mechanics, the Risk Review Agent owns metric interpretation, and the Governance Agent owns policy and disclosure checks.
Agent governance means bounded authority. The agent can prepare evidence, but it cannot decide suitability, guarantee returns, or replace the investment committee. Logs and artifacts make the workflow challengeable.
Part 4: Operating Model Code Path And Engine Controls
Related summary: Explains the article-specific engine path, code talk, strategy logic, and review controls. The section converts implementation details into trader language that can be challenged by risk, technology, and governance stakeholders.
The code path should be explained as a control map. Inputs feed indicators, indicators create entry and exit signals, the engine simulates orders, costs are applied, the ledger is written, and metrics summarize the path. That sequence replaces line-by-line recital with business-readable logic.
Signal logic and execution logic should remain separate. A signal may say conditions are favorable, but the engine must still check cash, position state, commission, risk exits, and ledger updates. This separation improves review quality.
This article focuses on operating model, agent roles, data controls, and top-ranked trend strategies. The reader should evaluate whether the code path makes those controls visible enough for a committee, risk reviewer, or technology owner to challenge.
Part 5: Top Strategy Records And Operating Lessons
Related summary: Reviews strategy records and lessons learned through return, volatility, Sharpe, drawdown, trade count, win rate, ledger quality, and operational feasibility. The section treats demo results as workflow evidence, not real market advice.
Strategy records should not be read as recommendations. They are evidence for comparing rule behavior, trade frequency, drawdown profile, and explainability. The numbers are especially limited when the data mode is deterministic offline demo data.
Lessons learned should be specific. A high-return strategy may have uncomfortable drawdown. A low-turnover strategy may be easier to govern. A high-trade-count strategy may create decision fatigue, slippage exposure, and operational burden.
Part 6: Executive Close And Governance Review
Related summary: Turns code, charts, and ledgers into committee language: what was tested, what improved, what failed, what remains uncertain, and why human judgment remains the final control before any production or allocation decision.
The close should translate research into governance language. The committee needs to know what was tested, what evidence was generated, which assumptions matter, what failed, and what remains a human decision.
A responsible close avoids victory language. It says that agents can help document assumptions, run repeatable tests, compare behavior, and prepare better reviews, while human judgment remains the final control.
Part 7: Operating Model Boundary And Governance Lenses
Related summary: Groups the integrated main-article details and governance lenses so readers can review policy, artifacts, demo-data limits, and accountability together.
Integrated Main-Article Detail 1: Operating Model Boundary
The operating model starts by separating research support from portfolio authority. The agent can validate scope, call a backtest tool, and prepare evidence, but it should not decide whether AMZN belongs in a reader portfolio.
Every run should leave artifacts that can be challenged: request payload, policy result, parameter record, data mode, trade ledger, chart output, metric summary, and exception notes.
Integrated Main-Article Detail 3: Human Approval Gate
The workflow is useful only when human review remains visible. The committee should receive the evidence package and decide whether the research is sufficient for further analysis, revision, or rejection.
Integrated Main-Article Detail 4: Cloud Control Layer
The AWS layer should separate raw data, curated tables, execution outputs, chart artifacts, and approval records so that technology teams can support retention, permissions, and reruns.
Governance Review Lens 1: Evidence Before Opinion
The research narrative should first identify data mode, rule logic, assumptions, costs, drawdown, and ledger availability. Opinion comes after evidence, not before it.
Governance Review Lens 2: Demo Data Boundary
When results come from offline deterministic demo data, the article should say so in the main body. Demo records are useful for workflow education and review design, not for making a real allocation decision.
Governance Review Lens 3: Ledger As Desk Memory
A trade ledger is the desk memory system. It shows when positions opened, when they closed, what size was used, which signal fired, and whether the process respected risk rules.
Governance Review Lens 4: Failure Mode Review
Professional readers should see failure modes before conclusions. Trend rules can whipsaw, recovery rules can miss persistent weakness, and active signals can create turnover that looks cleaner in a notebook than on a desk.
Governance Review Lens 5: Human Accountability
Agentic tools can gather, run, summarize, and organize, but the portfolio owner remains responsible for mandate fit, suitability, risk tolerance, and final judgment.
Part 8: AgentCore, Strands, And Code Talk Implementation
Related summary: Separates the operating model, Strands entrypoint, and custom engine code into one focused implementation section.
Series Focus
This post is part 1 of four and concentrates on operating model, agent roles, data controls, and top-ranked trend strategies. It uses Bedrock AgentCore and Strands Agents as the agentic operating model, the uploaded custom Cerebro-style engine as the code foundation, and the strategy summary records as the performance-review evidence. The discussion is educational, not a recommendation.
Bedrock AgentCore And Strands Agents Operating Model
The production design separates five responsibilities. The Quant Orchestrator receives the research request and decomposes it into data, strategy, execution, risk, and governance tasks. The Market Data Agent retrieves or validates AMZN and benchmark data. The Strategy Agent produces entry and exit signals. The Backtest Engine Tool runs the custom Cerebro-style simulation. The Risk Review Agent reads the trade ledger, performance metrics, and charts. The Governance Agent checks disclosures, long-only policy, data provenance, and suitability language.
AgentCore Runtime is the secure hosting layer for agents and tools, while Strands Agents provides a programming model for tool calling, orchestration, and agent behavior. In a regulated FSI environment, the agent should not directly approve a trade. It should create evidence, highlight uncertainty, and route outputs to human review.
A practical AWS data layer for this foundation article separates raw inputs, curated OHLCV tables, strategy code, result summaries, chart folders, and approval records. The point is lifecycle control: every later article can reuse the same storage pattern while focusing on a different strategy-review question.
Code Talk: Strands Agent And AgentCore Entrypoint
The Strands layer should not be a black box. The agent receives a research request, validates policy, calls the backtest tool, and returns a structured result. The tool should write immutable artifacts: parameter file, data snapshot identifier, trade ledger, chart path, and summary metrics. The governance check happens before and after execution.
from bedrock_agentcore.runtime import BedrockAgentCoreApp
from strands import Agent, tool
app = BedrockAgentCoreApp()
@tool
def validate_research_policy(symbol: str, side: str, derivatives: bool) -> dict:
if symbol != "AMZN":
return {"ok": False, "reason": "This workflow is scoped to AMZN research."}
if side != "long_only":
return {"ok": False, "reason": "Only long-only research is approved."}
if derivatives:
return {"ok": False, "reason": "Derivative instruments are outside policy."}
return {"ok": True, "reason": "Policy accepted."}
@tool
def run_custom_cerebro_strategy(strategy_name: str) -> dict:
return {
"strategy": strategy_name,
"status": "submitted",
"artifact_prefix": f"s3://amzn-research/backtests/{strategy_name}/"
}
quant_agent = Agent(tools=[validate_research_policy, run_custom_cerebro_strategy])
@app.entrypoint
def invoke(payload):
request = payload.get("request", "Run AMZN long-only timing research")
return quant_agent(request)
This code is deliberately conservative. The validation tool blocks unsupported scope before the backtest tool runs. The backtest tool returns artifact locations rather than emotional language. The agent can summarize, but the human committee remains accountable for decisions.
Code Talk: Custom Cerebro-Style Engine Logic
The custom engine is intentionally small. The constructor stores the price series, starting capital, allocation percentage, commission, stop-loss percentage, and take-profit percentage. Those parameters become the control surface that the Risk Agent and Governance Agent can inspect before the strategy runs.
The run method receives two Boolean time series: entry and exit. The Strategy Agent builds those series from indicators. The engine is responsible for execution discipline. It aligns signals to the price index, fills missing signal values as False, and then walks forward through time without looking ahead.
When the engine already owns shares, it checks three exit conditions: a strategy exit signal, a stop-loss breach, or a take-profit trigger. If one condition is true, the engine sells the long position, subtracts commission, updates cash, and records realized gross profit or loss in the trade ledger.
Part 9: Top Strategy Records And Trader Review
Related summary: Collects the top strategy records into a single performance-review section with code talk and lessons for each rule.
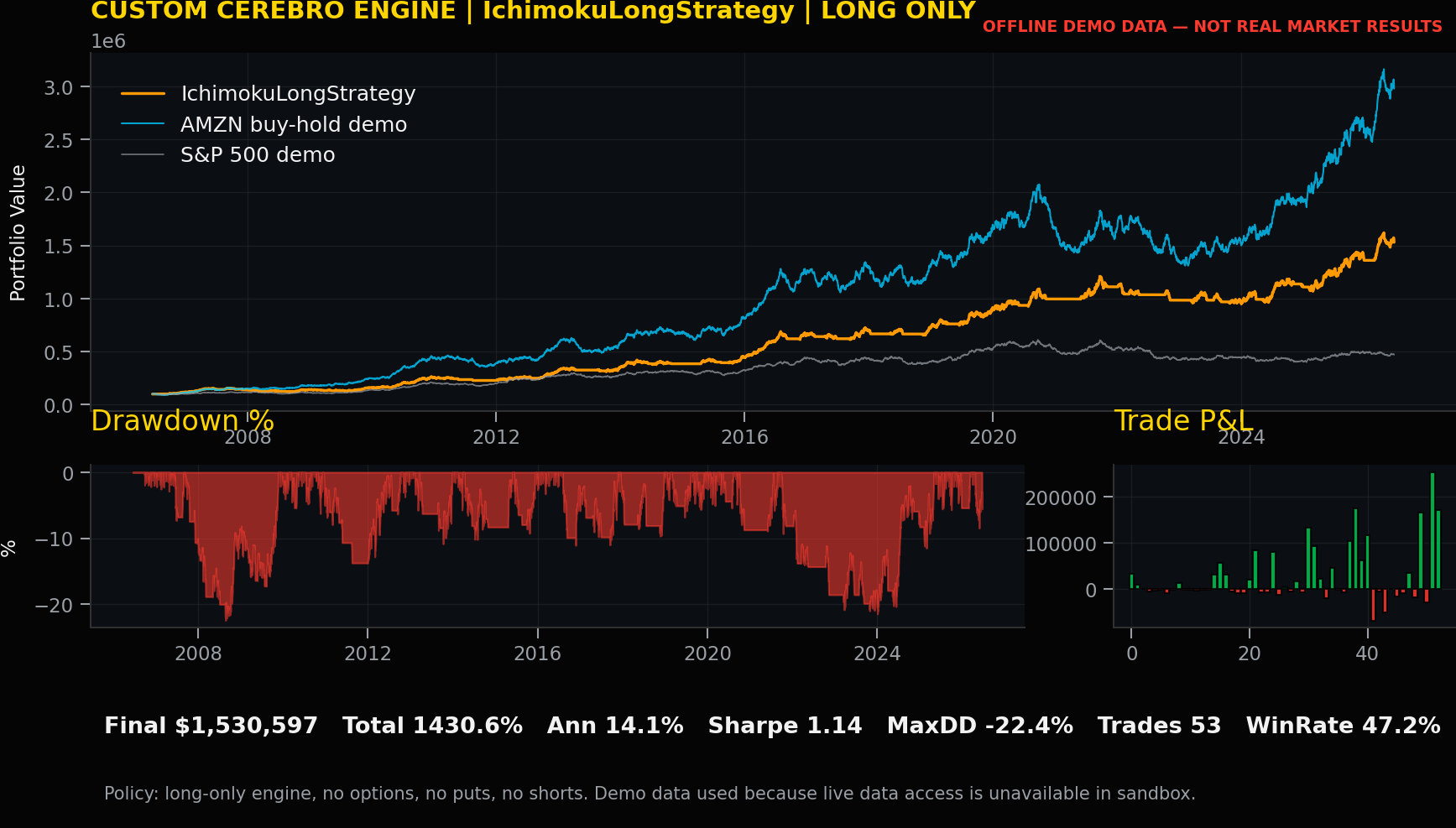
Strategy Record: IchimokuLongStrategy
Strategy Record: IchimokuLongStrategy
Code talk. IchimokuLongStrategy uses conversion line, base line, and cloud boundaries; trend structure comes before noise. For IchimokuLongStrategy, the signal definition should be reviewed separately from execution mechanics so the committee can distinguish market logic from order simulation, cost handling, and ledger production.
Performance review by trader. Total return was 1430.60%, annual return was 14.08%, volatility was 12.33%, Sharpe was 1.14, maximum drawdown was -22.43%, trades were 53, and win rate was 47.17%. These numbers are uploaded custom-engine offline demo records, not real market results.
Trading record and lesson learned. The lesson for IchimokuLongStrategy is to use the record as a review prompt: inspect explainability, turnover, drawdown tolerance, cost sensitivity, and whether the rule adds position-management insight beyond the headline return.
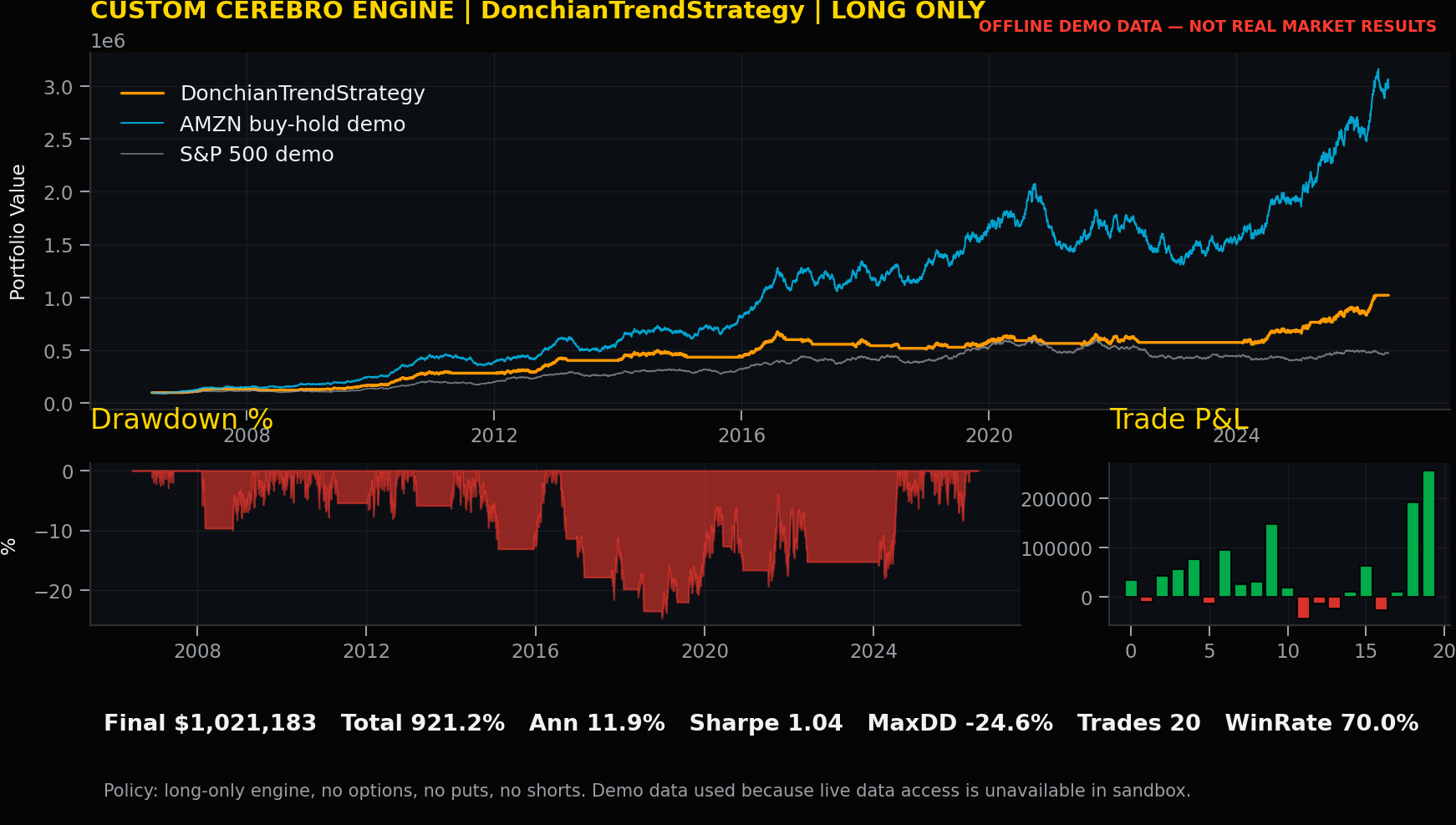
Strategy Record: DonchianTrendStrategy
Strategy Record: DonchianTrendStrategy
Code talk. DonchianTrendStrategy uses an eighty-day breakout with Nasdaq confirmation and a thirty-five-day channel exit. For DonchianTrendStrategy, the signal definition should be reviewed separately from execution mechanics so the committee can distinguish market logic from order simulation, cost handling, and ledger production.
Performance review by trader. Total return was 921.18%, annual return was 11.87%, volatility was 11.43%, Sharpe was 1.04, maximum drawdown was -24.64%, trades were 20, and win rate was 70.00%. These numbers are uploaded custom-engine offline demo records, not real market results.
Trading record and lesson learned. The lesson for DonchianTrendStrategy is to use the record as a review prompt: inspect explainability, turnover, drawdown tolerance, cost sensitivity, and whether the rule adds position-management insight beyond the headline return.
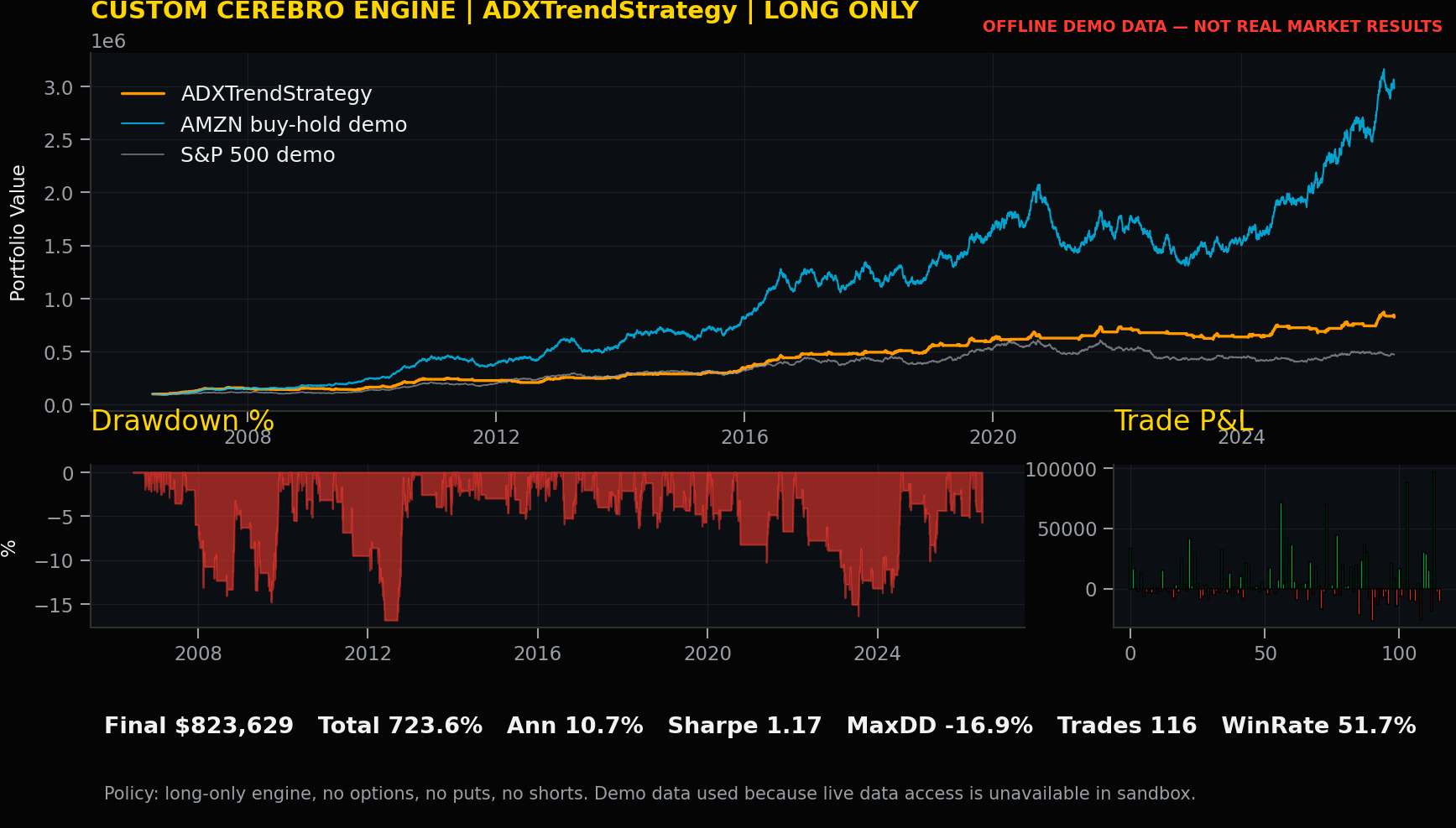
Strategy Record: ADXTrendStrategy
Strategy Record: ADXTrendStrategy
Code talk. ADXTrendStrategy requires ADX strength, positive directional movement, and price above a medium-term average. For ADXTrendStrategy, the signal definition should be reviewed separately from execution mechanics so the committee can distinguish market logic from order simulation, cost handling, and ledger production.
Performance review by trader. Total return was 723.63%, annual return was 10.72%, volatility was 9.13%, Sharpe was 1.17, maximum drawdown was -16.88%, trades were 116, and win rate was 51.72%. These numbers are uploaded custom-engine offline demo records, not real market results.
Trading record and lesson learned. The lesson for ADXTrendStrategy is to use the record as a review prompt: inspect explainability, turnover, drawdown tolerance, cost sensitivity, and whether the rule adds position-management insight beyond the headline return.
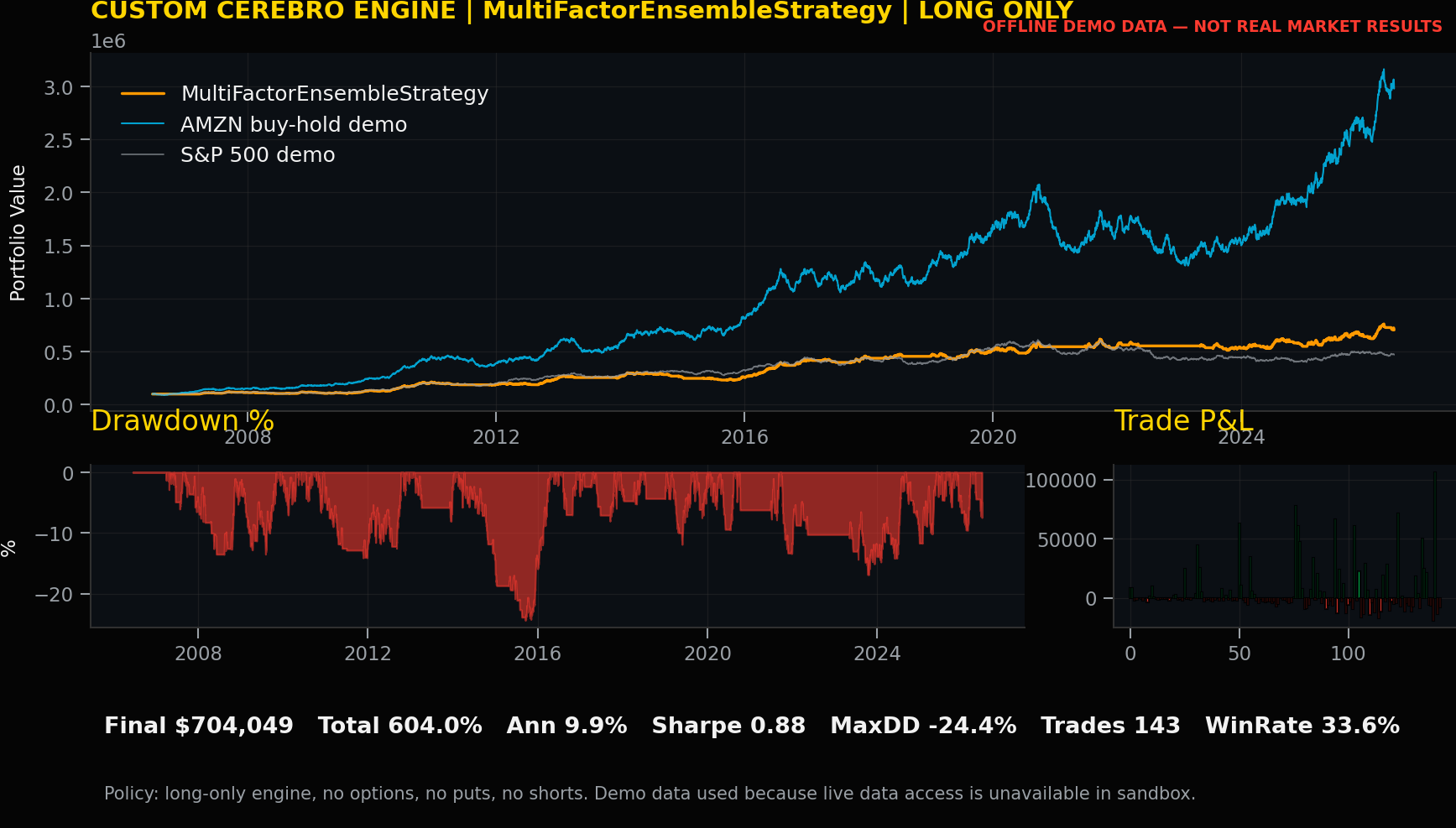
Strategy Record: MultiFactorEnsembleStrategy
Strategy Record: MultiFactorEnsembleStrategy
Code talk. MultiFactorEnsembleStrategy combines price trend, RSI, MACD, and S&P regime into a scorecard. For MultiFactorEnsembleStrategy, the signal definition should be reviewed separately from execution mechanics so the committee can distinguish market logic from order simulation, cost handling, and ledger production.
Performance review by trader. Total return was 604.05%, annual return was 9.88%, volatility was 11.23%, Sharpe was 0.88, maximum drawdown was -24.44%, trades were 143, and win rate was 33.57%. These numbers are uploaded custom-engine offline demo records, not real market results.
Trading record and lesson learned. The lesson for MultiFactorEnsembleStrategy is to use the record as a review prompt: inspect explainability, turnover, drawdown tolerance, cost sensitivity, and whether the rule adds position-management insight beyond the headline return.
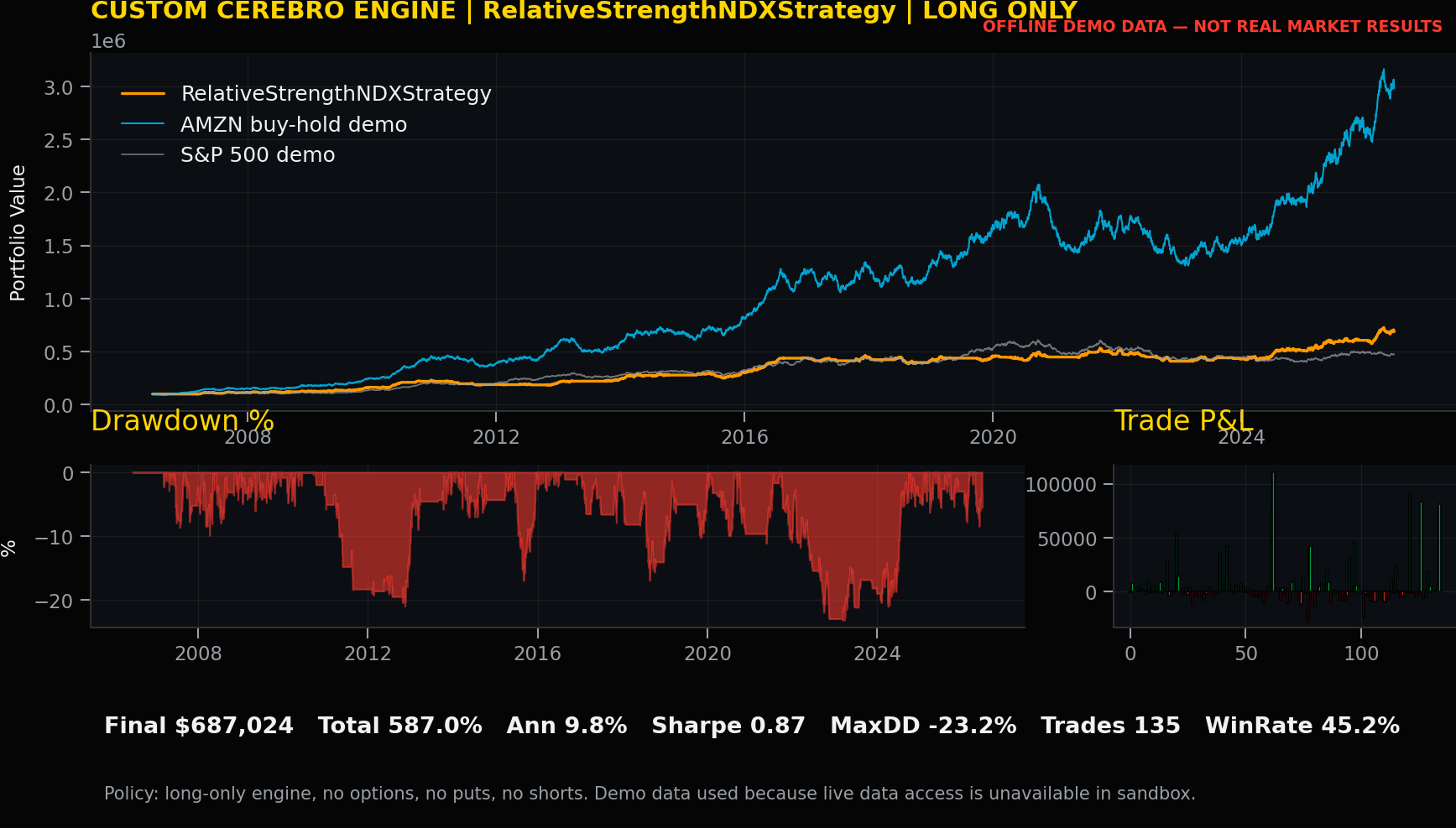
Strategy Record: RelativeStrengthNDXStrategy
Strategy Record: RelativeStrengthNDXStrategy
Code talk. RelativeStrengthNDXStrategy compares AMZN against Nasdaq 100 and enters on relative-strength improvement. For RelativeStrengthNDXStrategy, the signal definition should be reviewed separately from execution mechanics so the committee can distinguish market logic from order simulation, cost handling, and ledger production.
Performance review by trader. Total return was 587.02%, annual return was 9.75%, volatility was 11.17%, Sharpe was 0.87, maximum drawdown was -23.23%, trades were 135, and win rate was 45.19%. These numbers are uploaded custom-engine offline demo records, not real market results.
Trading record and lesson learned. The lesson for RelativeStrengthNDXStrategy is to use the record as a review prompt: inspect explainability, turnover, drawdown tolerance, cost sensitivity, and whether the rule adds position-management insight beyond the headline return.
Part 10: Trading Lessons, Evidence Notes, And Governance Close
Related summary: Finishes with trading lessons, source notes, committee narrative, and final governance checklist.
Trading Records And Lessons Learned
A trade record is more than a receipt. It is a memory system for the desk. Each entry date asks whether the trader had a repeatable signal or only a story. Each exit date asks whether the process respected risk or waited for emotion to negotiate. Each drawdown asks whether the sizing rule was honest about volatility.
The first lesson in the operating-model article is that process evidence must come before performance interpretation. A ranked table is only useful when reviewers know the data mode, rule logic, execution assumptions, cost treatment, and artifact locations.
The second lesson is that agent roles should be narrow enough to challenge. The orchestrator can coordinate, the engine can simulate, and the reviewer can summarize, but none of those components should quietly become a portfolio decision maker.
The third lesson is that the operating model should expose strategy personality before anyone argues about preference. Low-turnover rules, high-Sharpe rules, and high-activity rules create different review obligations, so the artifact package should make those differences visible.
Source And Evidence Notes
This article uses the uploaded custom engine artifacts as its performance discussion source. The manifest states that the engine is CustomCerebroEngine, the data mode is deterministic offline demo data, the strategy count is twenty, the image count is twenty-two, and the rules are long-only with no options, no puts, and no shorts. The strategy summary file ranks all twenty strategies by total return, annual return, volatility, Sharpe, maximum drawdown, trades, and win rate. The uploaded code file supplies the engine structure, indicator definitions, signal map, metrics function, and Bloomberg dark-mode chart generation approach.
External architecture references: Amazon Bedrock AgentCore documentation describes AgentCore as a managed service for deploying and operating agents securely at scale, and AgentCore Runtime as a secure serverless environment supporting frameworks such as Strands, LangGraph, and CrewAI. Strands documentation describes deploying Strands Agents to AgentCore Runtime and using Python integration patterns for agent entrypoints. Backtrader documentation is referenced conceptually for the Cerebro pattern of gathering data feeds, strategies, analyzers, observers, and plotting facilities.
Committee Close Narrative
Here is the closing message to rehearse before presenting the research:
We are not here to celebrate a gain. We are here to inspect the process behind the gain. The Amazon position has been strong, but strength does not remove the need for risk discipline. We built a custom engine, organized twenty timing strategies, reviewed the records, and separated research evidence from recommendation language.
The correct conclusion is not that an agent should trade for us. The correct conclusion is that agents can help us document assumptions, run repeatable tests, compare strategy behavior, expose weak logic, and prepare better conversations with risk, technology, and governance teams. Human judgment remains the final control.
Final Governance Checklist
Confirm the workflow is education and planning support, not investment advice.
Confirm the position language is long-only and avoids derivative implementation.
Confirm whether results are real-data backtests or offline demo outputs.
Confirm each strategy has a trade ledger, equity curve, drawdown path, and performance summary.
Confirm code, data, parameters, and charts are versioned together.
Confirm the investment committee understands limitations before discussing any allocation decision.